Pages in this section:
All sections:
Adding sentiment
How to add sentiment?
You can now auto-code the sentiment of the consequence factor in each link.
You only have to do this once, and it takes a little while, so wait until you’ve finished coding all your links.
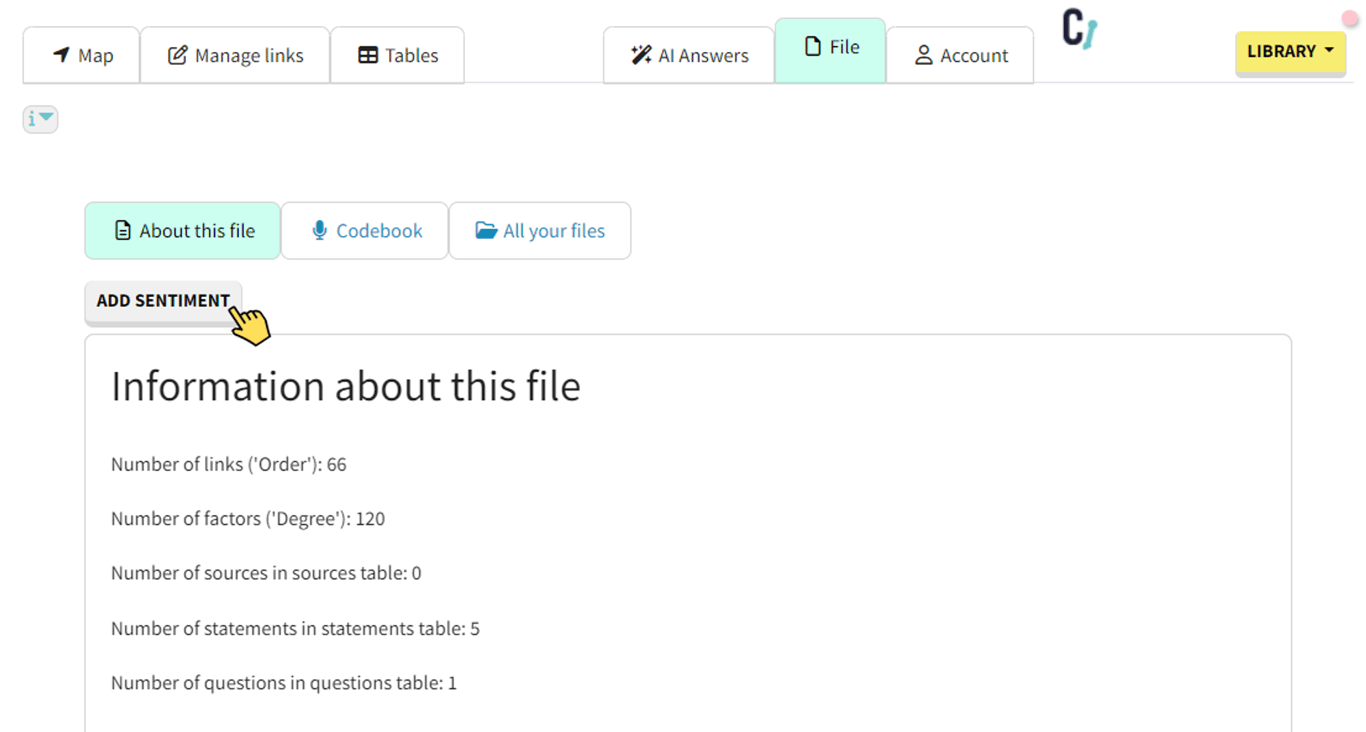
When you are ready, click on the File tab, and under the ‘About this file’, there’s the ‘ADD SENTIMENT’ button. You just have to click on it and wait for the magic to happen
So each claim (actually, the consequence of each claim) now has a sentiment, either -1, 0 or 1.
Many links are actually a bundle of different claims. We can calculate the sentiment of any bundle, as simply the average sentiment. So an average sentiment of -1 means that all the claims had negative sentiment. An average of zero means there were many neutral sentiments and/or the positive and negative sentiments cancel each other out.
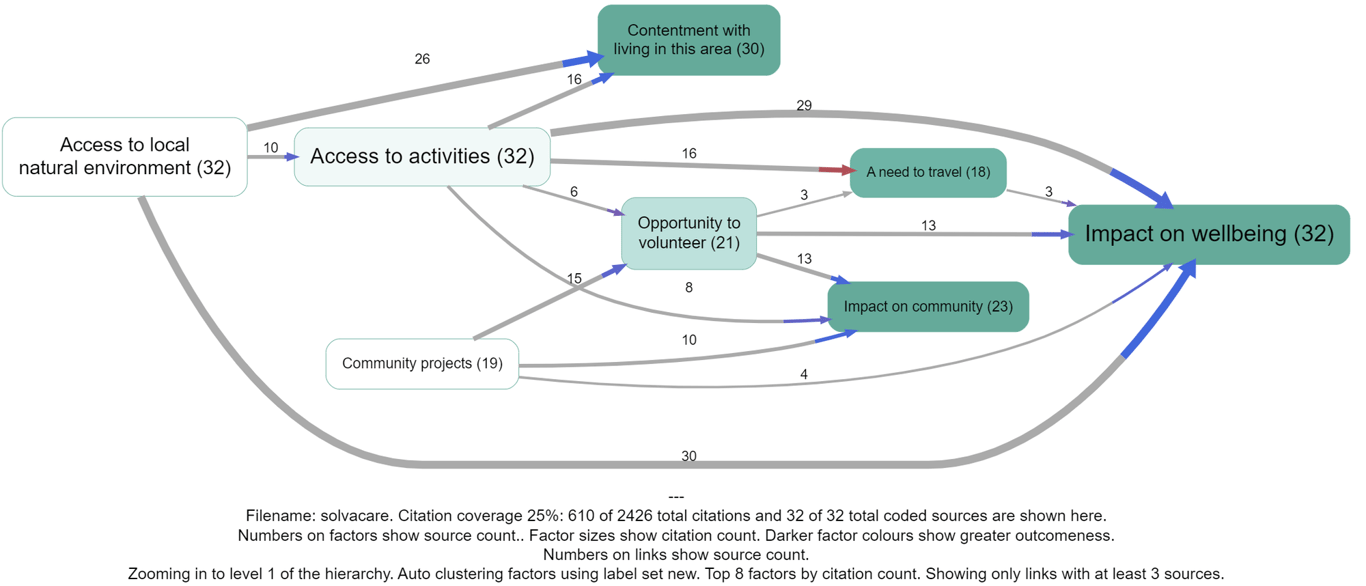
Only the last part is coloured, because the colour only expresses the sentiment of the effect, not the cause.
Once you have autocoded sentiment for your file, you can switch it on or off using 🎨 Formatters: Colour links.
Tip
When displaying sentiment like this, reduce possible confusing by making sure that you either use only neutral factor labels like Health rather than Good health or Improved Health: an exception is if you have pairs of non-neutral labels like both Poor health alongside Good health. You can do this either in your raw coding or using ✨ Transforms Filters: 🧲 Magnetic labels or 🗃️ Canonical workflow
Adding some colour: a discussion of the problem of visualising contrary meanings
The problem
We’ve already described our approach to making sense of texts at scale by almost-automatically coding the causal claims within them, encoding each claim (like “climate change means our crops are failing”) as a pair of factor labels (“climate change” and “our crops are failing”): this information is visualised as one link in a causal map. We use our “coding AI” to code most of the causal claims within a set of documents in this way. We have had good success doing this quickly and at scale without providing any kind of codebook: the AI is free to create whatever factor labels it wants.
There is one key remaining problem with this approach. Here is the background to the problem: if the coding AI is provided with very long texts, it tends to skip many of the causal claims in fact contained in the documents. Much shorter chunks of text work best. As we work without a codebook, this means that the AI produces hundreds of different factor labels which may overlap substantially in meaning. In turn this means that we have to cluster the labels in sets of similar meaning (using phrase embeddings and our “Clustering AI”) and find labels for the sets. This all works nicely.
But the problem is that, when we use phrase embeddings to make clusters of similar labels, seeming opposites are often placed quite close together. In the space of all possible meanings, unemployment and employment are quite close together – they would for example often appear on the same pages of a book – and both are quite far from a phrase like, say, “climate change”. But this is unsatisfactory because if in the raw text we had a link describing how someone lost their job, coded with an arrow leading to a factor unemployment alongside another piece of text describing how someone gained work, represented by an arrow pointing to employment if these two labels are combined, say into employment or employment issues the items look very similar and we seem to have lost some essential piece of information.
Can’t we use opposites coding?
In ordinary manual coding (see ➕➖ Opposites) we solve this problem by marking some factors as contrary to others using our
~ notation (in which ~Employment can stand for Unemployment, Bad employment, etc) and this works well. However while it is possible to get the coding AI to code using this kind of notation, it is not part of ordinary language and is therefore not understood by the embeddings API: the ~ is simply ignored even more often than the difference between Employment and Unemployment. In order to stop factors like employment and unemployment ending up in the same cluster it is possible to exaggerate the difference between them by somehow rewriting employment as, say, “really really crass absence of employment” but this is also unsatisfactory (partly because all the factors like really really crass X tend to end up in the same cluster).New solution
So our new solution is simply to accept the way the coding-AI uses ordinary language labels like employment and unemployment and to accept the way the embedding-AI clusters them together. Instead, we recapture the lost “negative” meaning with a third AI we call the “labelling AI”. This automatically codes the sentiment of each individual causal claim so that each link is given a sentiment of either +1, 0 or -1. For this third step we use a chat API. The instruction to this third AI is:
"I am going to show you a numbered list of causal claims, where different respondents said that one thing ('the cause') causally influenced another ('the effect') together with a verbatim quote from the respondent explaining how the cause led to the effect.
The claims are listed in this format: 'quote ((cause --> effect))'.
The claims and respondents are not related to one another so treat each separately.
For each claim, report its *sentiment*: does the respondent think that the effect produced by the cause is at least a bit good (+1), at least a little bad (-1) or neutral (0).
Consider only what the respondent thinks is good or bad, not what you think.
If you are not sure, use the neutral option (0).
NEVER skip any claims. Provide a sentiment for every claim."
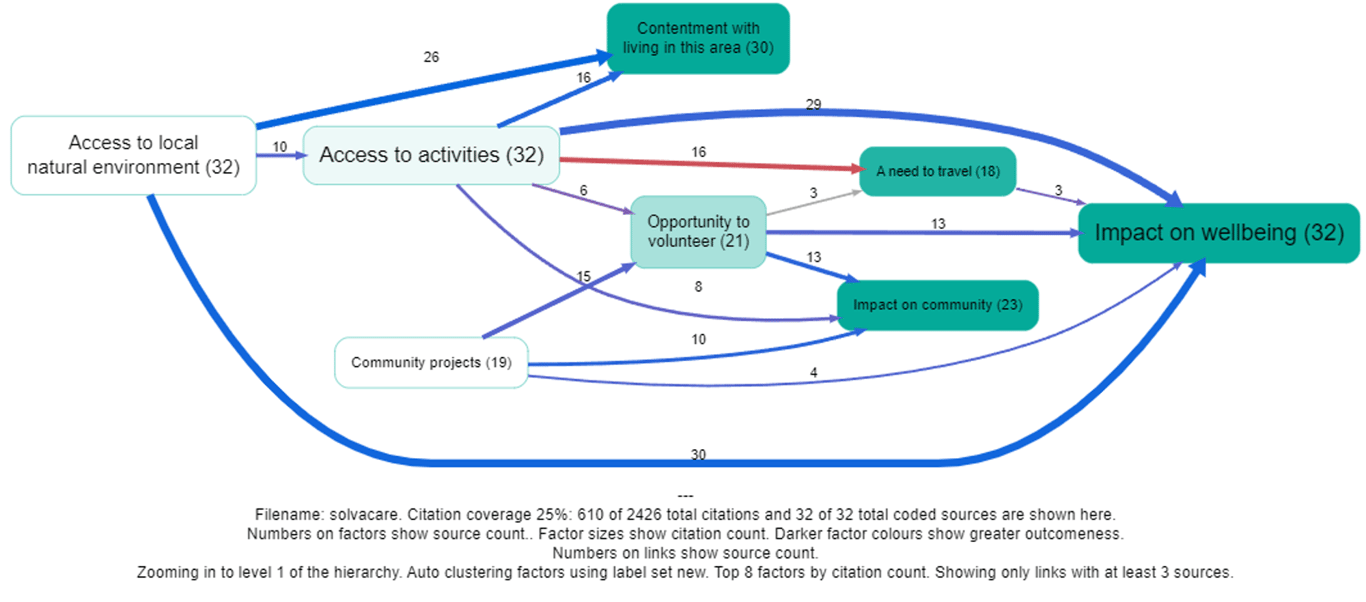
The previous solution coloured the whole link which was fine in most cases but led to some really confusing and incorrect coding where the influence factor was involved in the opposite sense, as in Access to activities below. One might assume that the red links actually involve some kind of negative (or opposite?) access to activities, but we don't actually know that because it wasn't coded as such. Other alternatives would be to also automatically separately code the sentiment of the first part of the arrow, but this doesn't work because sometimes the sentiment is not in fact negative. We would have to somehow automatically code whether the influence factor is meant in an opposite or contrary sense but this is hard to do.